
On January 27th 2026, DeepSeek released DeepSeek-OCR 2 on HuggingFace and GitHub, accompanied by a comprehensive research paper.
This new model represents a major breakthrough in document processing, introducing Visual Causal Flow—a technology that allows the model to dynamically reorder visual tokens based on content, rather than following a fixed scanning pattern. Unlike the original DeepSeek-OCR which focused on visual compression, OCR 2 takes a different approach by enabling the model to understand and process documents more like humans do.
The release has attracted significant attention, as it demonstrates substantial improvements in accuracy, reading order understanding, and production reliability.
1. What is OCR: Definition and Traditional Limitations
Optical Character Recognition (OCR) technology converts images of text into machine-readable text. Traditional OCR systems and early vision-language models (VLMs) rely on fixed raster-scan processing—reading images left-to-right, top-to-bottom—which contradicts how humans naturally perceive visual information. This mechanical approach has been the standard for decades, but it fundamentally misaligns with semantic understanding.
The rigid raster-scan order creates significant problems when processing complex document layouts. When a VLM encounters a table with multiple columns, it processes the header row, then jumps to column 2 row 1, then column 2 row 2, before finally returning to column 1 rows—creating illogical token sequences. Similarly, multi-column text, formulas interspersed with explanatory text, and mixed content types are read in unnatural sequences, causing the model to misunderstand information relationships.
This leads to three critical failures: lower accuracy on complex documents, incorrect reading order interpretation (where related information is scattered across the sequence), and higher error rates in production environments including text duplication and hallucination. The fundamental problem is that traditional VLMs don't understand the semantic flow of information—they just follow a mechanical scanning pattern.
2. DeepSeek-OCR 2's Solutions
Visual Causal Flow: The Core Innovation
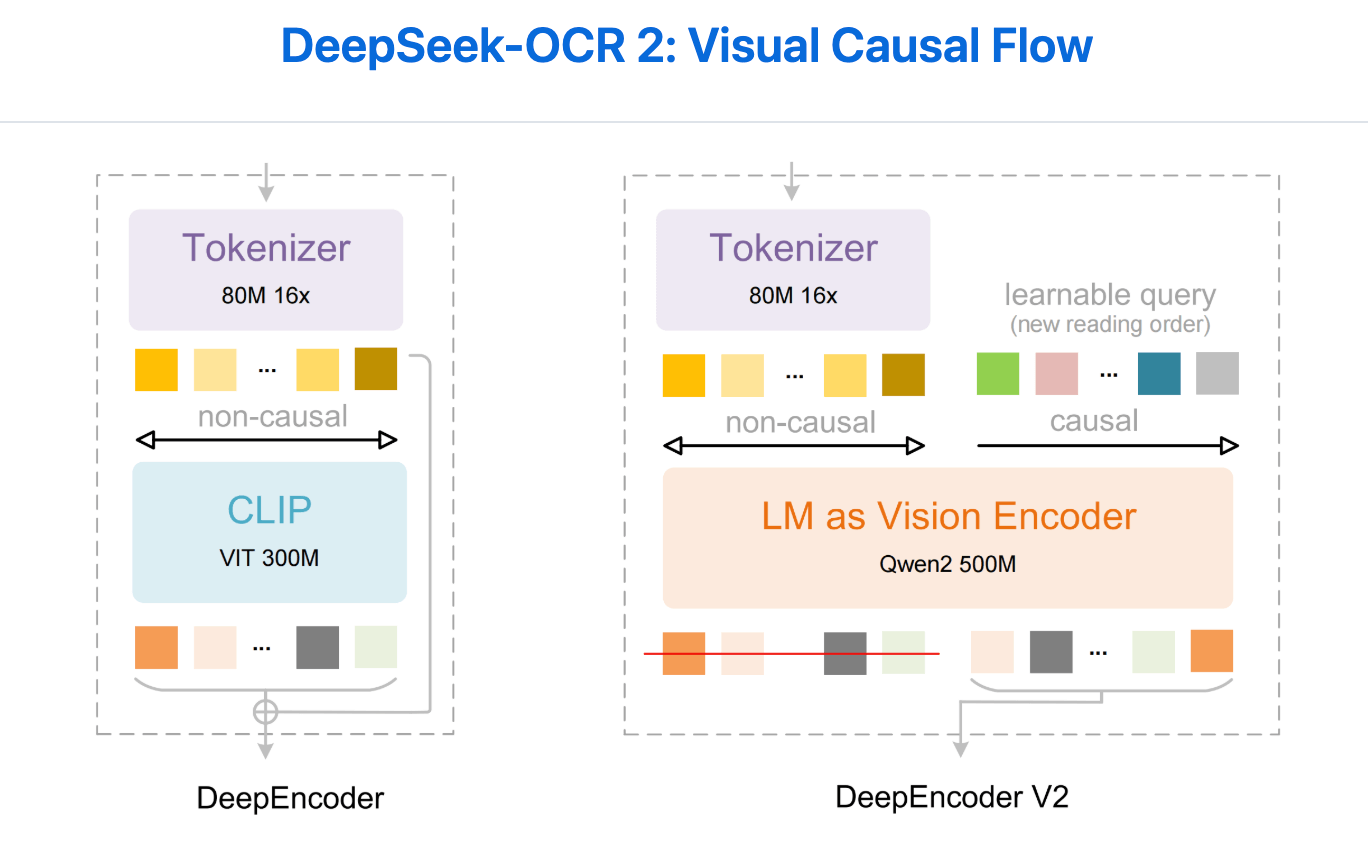
DeepSeek-OCR 2 introduces a revolutionary concept called Visual Causal Flow, which grants the model the ability to dynamically reorder visual tokens based on image content and semantic relationships. Rather than adhering to a fixed raster-scan pattern, the model now understands the logical flow of information within a document and reorganizes visual tokens to match that logical sequence. This is fundamentally different from previous approaches—it's not just better compression or smarter feature extraction, but a complete reimagining of how visual information should be sequenced for language models.
The key insight is that visual understanding should be causal: the model should reason about which visual elements logically precede others, similar to how humans trace the flow of information through a complex document. When reading a table, humans don't scan mechanically left-to-right; they understand that the header row provides context, then read each column's data in order. DeepSeek-OCR 2 replicates this reasoning process.
DeepEncoder V2 powers Visual Causal Flow through four key innovations:
Innovation 1: Compact LLM Backbone
The original DeepEncoder used CLIP as its visual encoding backbone. DeepSeek-OCR 2 replaces CLIP with Qwen2-0.5B, a compact LLM architecture. This enables the encoder to leverage language understanding capabilities and reason about visual content semantically. Using a language model as the visual encoder allows understanding of semantic relationships between visual elements, not just visual features. Qwen2-0.5B balances semantic understanding capability with computational efficiency.
Innovation 2: Hybrid Attention Mechanism
The architecture uses dual-component attention. Visual tokens use bidirectional attention (ViT-style), allowing each token to attend to all others without directional constraints. This captures full image context and distant relationships. Simultaneously, learnable query tokens handle causal flow queries, attending to all visual tokens and previous queries to perform logical reordering. Bidirectional attention handles context understanding, while causal attention handles logical sequencing.
Innovation 3: Cascaded Causal Reasoning
The two-level cascaded structure changes how visual information flows. The encoder uses query tokens to perform semantic reordering, creating an ordered sequence respecting document content flow. The LLM decoder then processes this intelligently ordered sequence. Both stages work in harmony—the decoder focuses on understanding content rather than figuring out reading order, improving efficiency and accuracy.
Innovation 4: Intelligent Token Compression
Visual tokens are controlled at 256-1,120 range depending on image complexity. This maintains high compression while staying within token budgets of models like Gemini 3 Pro. Compression doesn't sacrifice quality because tokens are intelligently reordered and semantically prioritized. Table headers get more tokens than decorative elements; text-heavy regions get more tokens than whitespace.
Performance Improvements
The innovations deliver measurable improvements: 91.09% accuracy on OmniDocBench v1.5 (+3.73% vs original), reading order edit distance reduced from 0.085 to 0.057 (32.9% improvement), production duplication rate dropped from 6.25% to 4.17% (33.3% reduction), and maximum 1,120 visual tokens enabling faster inference and better scalability.
3. Influence and Future Trends
Current Impact and Industry Applications
DeepSeek-OCR 2 sets a new standard for document understanding across multiple industries. Financial institutions can now process complex financial statements, invoices, and contracts with significantly higher accuracy. Legal firms can extract information from multi-page documents with correct reading order preservation. Academic institutions can analyze research papers with improved formula and figure recognition. E-commerce companies can extract product information from diverse document formats more reliably.
The open-source release democratizes access to state-of-the-art OCR technology, enabling startups and smaller organizations to build sophisticated document processing pipelines without massive R&D investments. This has significant implications for digital transformation initiatives globally.
Future Directions and Research Implications
DeepSeek has outlined ambitious plans for future development. The team intends to explore implementing true 2D image understanding and reasoning through a cascaded approach using two 1D causal reasoners. This evolution would further enhance the model's ability to understand spatial relationships and complex visual layouts that require simultaneous horizontal and vertical reasoning.
Beyond OCR, the Visual Causal Flow concept has broader implications for vision-language models. The principle of dynamically reordering visual tokens based on semantic content could be applied to other VLM tasks, potentially improving performance across document understanding, visual question answering, and image captioning. This represents a paradigm shift in how VLMs should process visual information—moving away from fixed scanning patterns toward intelligent, content-aware sequencing.
Emerging Trends in Document AI
The success of Visual Causal Flow is likely to inspire similar approaches in the broader AI community. We can expect to see more research into semantic-aware token ordering, hierarchical document understanding, and context-aware visual processing. The combination of language models with visual understanding is becoming increasingly sophisticated, and DeepSeek-OCR 2 demonstrates that architectural innovation in token sequencing can yield significant performance gains.
Your AI Receptionist, Live in Minutes.
Scale your front desk with an AI that never sleeps. Solvea handles unlimited multi-channel inquiries, books appointments into your calendar automatically, and ensures zero missed opportunities around the clock.
4. Conclusion
DeepSeek-OCR 2 represents a fundamental paradigm shift in how machines understand visual information. By introducing Visual Causal Flow and the innovative DeepEncoder V2 architecture, the model addresses core limitations of traditional approaches that have persisted for decades. The combination of superior accuracy (91.09%), improved reading order understanding (32.9% better), enhanced production reliability (33.3% fewer duplications), and exceptional efficiency (1,120 max tokens) makes it a transformative solution for document processing.
The architectural innovations—compact LLM backbone, hybrid attention mechanism, cascaded reasoning, and intelligent compression—work together to enable the model to process documents the way humans do: understanding semantic flow rather than following mechanical scanning patterns. With open-source availability on HuggingFace and GitHub, these advances are immediately accessible to the global community. DeepSeek-OCR 2 is not just an incremental improvement over previous OCR systems—it represents a new era in document understanding where machines can reason about visual information with human-like semantic awareness.





